Creating PostgreSQL Test Data with SQL, PL/pgSQL, and Python
Explore different ways of generating test data with PostgreSQL.
Greg Schaberg
Senior Infrastructure and Web
Apr 30, 2021

After exploring various ways to load test data into PostgreSQL for my last blog post, I wanted to dive into different approaches for generating test data for PostgreSQL. Generating test data, rather than using static manually-created data, can be valuable for a few reasons:
Writing the logic for generating test data forces you to take a second look at your data model and consider what values are allowed and which values are edge cases.
Tools for generating test data make it easier to set up data per test. I would argue this is better than the alternatives of (a) hand-creating data per test or (b) trying to maintain a single dataset that is used across the entire test suite. The first option is tedious, and the second option can be brittle. As an example, if you're testing an e-commerce website and your test suite uses hard-coded product details and deactivating the product in your test dataset causes many tests to unexpectedly fail, then those tests were reliant on a pre-condition that happened to be satisfied in your test dataset. Generating data per test can make such pre-conditions more explicit and clear, especially for colleagues who inherit your tests and test data in the future.
Unless you already have a large dataset from a production environment or a partner company that you can use (hopefully after anonymization!), generating test data is the only way to get large datasets for benchmarking and load testing.
Similar to the previous article, if you're using an Object-Relational Mapping (ORM) library, then you'll probably create and persist objects into the database using the ORM or use the ORM to dump and restore test data fixtures using JSON or CSV. If you're not using an ORM, the approaches in this article may provide some learning or inspiration for how you can best generate data for your particular testing situation.
Follow Along with Docker
Similar to the previous article, you can follow along using Docker and the scripts in a subfolder of our Tangram Vision blog repo: https://gitlab.com/tangram-vision-oss/tangram-visions-blog/-/tree/main/2021.04.30_GeneratingTestDataInPostgreSQL
Unlike the previous article, I've provided a Dockerfile to add Python into the Postgres Docker image so we can run Python inside the PostgreSQL database. As described in the repo's README, you can build the docker image and run examples with:
The repo contains a variety of files that start with add-data- which demonstrate different ways of loading and generating test data. After the Postgres Docker container is running, you can run add-data- files in a new terminal window with a command like:
If you want to interactively poke around the database with psql , use:
Sample Schema
For example code and data, I'll use the following simple schema again:
Musical artists have a name
An artist can have many albums (one-to-many), which have a title and release date
Genres have a name
Albums can belong to many genres (many-to-many)
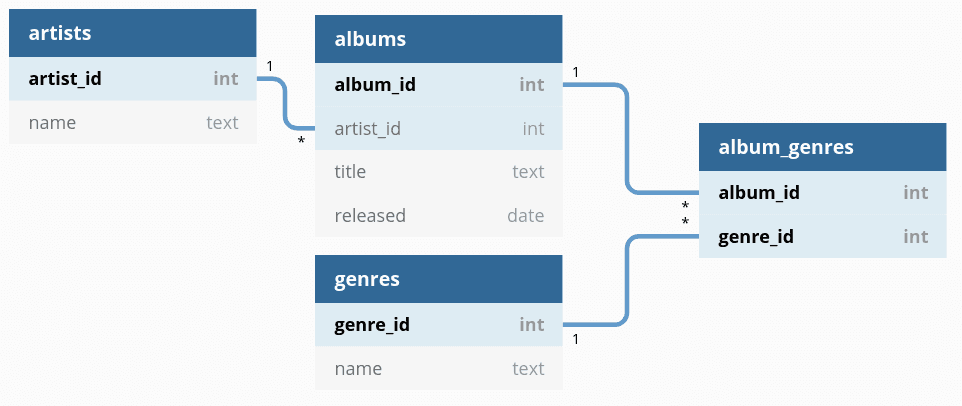
Sample schema relating musical artists, albums, and genres.
Generating Data
Using static datasets has advantages (you know exactly what data is in your database), but they can be tedious to maintain over time and impractical to create if you need a lot of data (e.g. for benchmarking or load testing). Generating data is an alternative approach which lets you define how data should look in one place and then generate and use as much data as you like.
There are a few different tools for generating test data that are worth exploring, from plain ol' SQL to higher-level programming languages like Python.
SQL
If you're like me, you may have started this article not expecting SQL to be capable of generating test data. With generate_series and random and a little creativity, however, SQL is well-equipped to generate a variety of data.
To create 5 artists with 8 random hex characters for their names, you can do the following:
If you want to use random words instead of random hex characters, you can pick words from the system dictionary. I've copied Ubuntu's american-english word list to /usr/share/dict/words in the Docker image, so we just need to load it and pick a word randomly:
No joke, the first word that the above query returned for me was "bravo". I don't know whether to be encouraged or creeped out.

❕ On a separate note, the dictionary contains words that may be offensive and inappropriate in some settings. If you're pulling test data from the dictionary and don't want these words to pop up in your next demo to customers/bosses, make sure to take appropriate precautions!
Anyway, moving on... using these tools (and a few more), we can generate interesting test data for all of our tables. Comments in the code below explain extra functions and techniques being used.
But that's not all! We can define functions in SQL to reuse logic — if we want genres, artist names, and album titles to all be random words, then we can move random-word-picking into a function and use it in many places:
PL/pgSQL
If the declarative style of SQL is awkward/difficult, we can turn to PL/pgSQL to generate test data in PostgreSQL using a more procedural/imperative programming style. PL/pgSQL provides familiar programming concepts like variables, conditionals, loops, return statements, and exception handling.
To demonstrate some of what PL/pgSQL can do, let's specify some more requirements for our generated data — roughly half of our artists should have names starting with "DJ" and all albums by DJ artists should belong to an "Electronic" genre. That implementation might look like:
As you can see in the above code snippet, PL/pgSQL lets us:
Test conditions with IF statements (which can have ELSIF and ELSE blocks or alternately be represented with CASE statements),
Loop over a range of integers with
FOR i IN 1..8 LOOP(which can loop in reverse or with a step),Loop over rows from a query, as in the
FOR dj_album IN ...example above,Print helpful log statements with RAISE,
and do all the above in a performant way, because the client can send the whole code block to the server to execute, rather than serializing and sending each statement to the server one at a time as it would with raw SQL.
There's much more to learn about PL/pgSQL than I can cover here in a reasonable amount of space, but hopefully the above provides some insight into its capabilities to help you decide what tool makes sense for you!
Using Python
PL/pgSQL isn't the only procedural language available with PostgreSQL, it also supports Python! The Python procedural language, plpython3u for Python 3, is "untrusted" (hence the u at the end of the name), meaning you must be a superuser to create functions, and Python code can access and do anything that a superuser could. Luckily, we're generating test data in non-production environments, so Python is an acceptable option despite these security concerns.
To use plpython3u , we need to install python3 and postgresql-plpython3-$PG_MAJOR system packages and create the extension in the SQL script with the command below. I've already taken these steps for the Docker image and plpython script in the sample code repo.
The main difference to be aware of when using Python in PostgreSQL is that all database access happens via the plpy module that is automatically imported in plpython3u blocks. The following example should help clarify some basics of using plpython3u and the plpy module:
Here are the most important insights from the above code:
You can't print out debugging information with the Python print statement, you need to use logging methods available in the plpy module (such as
info,warning,error).The
plpy.executefunction can execute a simple string as a query. If you're interpolating variables into the query, you are responsible for converting the variable value into a string and properly quoting it.Alternately, use
plan = plpy.preparethenplan.executeto prepare and execute a query, which allows you to leave data conversion and quoting up to PostgreSQL. As a bonus, you can save plans so the database only has to parse the query string and formulate an execution plan once.The return value of
plpy.executecan tell you the status of the query, how many rows were inserted or returned, and the rows themselves.
Now that we have an understanding of how to use Python in PostgreSQL, let's apply it to generating test data for our sample schema. While we could translate the previous section's PL/pgSQL code to Python with very few changes, doing so wouldn't capitalize on the biggest advantage of using Python — the plethora of standard and third-party libraries available.
The Faker Package
Faker is a Python package that provides many helpers for generating fake data. You can generate realistic-looking first and last names, addresses, emails, URLs, job titles, company names, and much more. Faker also supports generating random words and sentences, and generating random data across many different data types (numbers, strings, dates, JSON, and more). Using Faker is straightforward:
The dataclasses Module
If you prefer to create Python objects to represent rows from your different tables, you could use a variety of different packages, such as attrs, factory_boy, or the built-in module dataclasses. These packages allow you to declare a field per table column and associate data types and factories for generating test data.
❕ Please note that if you go very far down this path of representing rows as Python objects, you will find yourself re-creating a lot of ORM functionality. In that case, you should probably just use an ORM!
Here's an example of how you could use the dataclasses module to generate test data for our sample schema:
The above snippet defines classes for each main table in our example schema: Genre, Artist, and Album. Then, it defines fields for each column along with a default_factory function that tells Python (or the Faker package, in many cases) how to generate suitable test data. I made the Album class the "owner" of the many-to-many relationship with Genres, so when an Album is created, it automatically picks 0-3 existing Genres to associate itself with during initialization.
The second half of the code passes the Python objects into SQL INSERT queries, returning the primary key IDs (which weren't generated during object creation, due to the init=False field argument) so they can be saved on the objects and used later when setting foreign keys. This highlights a difficulty with doing this sort of object-relational mapping yourself — you have to figure out dependencies between your types of data and enforce an ordering (in Python and SQL) so that you have database-created IDs at the right times. This can be a bit tedious and messy, especially if you have circular dependencies or self-referencing relationships in your tables.
Importing External .py Files
If your data model or data-generation code start to get complex, it can be annoying to have a lot of Python code in SQL files — your IDE won't want to lint, type-check, and auto-format your Python code! Luckily, you can keep your Python code in external .py files that you import and execute from inside a plpython3u block, using the technique shown below:
The add_test_data.py file can look the exact same as the body of the plpython3u block from the previous example, but you'll need to wrap the bottom half (which uses plpy to run queries) in a function that accepts plpy as an argument, so it looks like:
Other (Trusted) Ways to Use Python
I want to briefly touch on two ways of using Python outside of PostgreSQL — running Python externally may be preferable if you want or need to avoid the untrusted nature of plpython3u . These approaches let you maintain your Python code completely independent of the database, which may be beneficial for reusability and maintainability.
You could use Python scripts to generate test data into CSV files and then load those into PostgreSQL with the COPY command. With this approach, however, you will likely end up with a multi-step process to generate and load test data. If you invoke a Python script (which outputs CSV) within the SQL COPY command, then you can't populate multiple tables with a single command. If you use multiple SQL COPY commands, it becomes convoluted to reference IDs across tables (foreign keys) across multiple Python script executions. The remaining reasonable approach is a multi-step one: run a Python script that saves multiple CSV files to disk (one per database table) and then run an SQL COPY command per CSV file to load the data.
You could run Python scripts that connect to PostgreSQL via a client library such as psycopg2. The psycopg2 package is used by many ORMs, such as the Django ORM and SQLAlchemy, but it doesn't impose any restrictions on how you handle your data — it just provides a Python interface for connecting to PostgreSQL, sending SQL commands, and receiving results.
Thank you for joining me on this exploration of loading test data (in the previous blog post) and generating test data for PostgreSQL! We tried out a variety of approaches and got some hands-on experience with code — I hope this helps you understand how to use these different approaches, weigh their tradeoffs, and choose which approach makes the most sense for your team and project.
If you have any suggestions or corrections, please let me know or send us a tweet, and if you’re curious to learn more about how we improve perception sensors, visit us at Tangram Vision.

